Abstract
Background: Traditional dietary assessment methods, such as 24-hour recalls and food records, are limited by subjective bias, resource demands, and human or model error. These constraints have prompted exploration of more reliable and accessible alternatives, including digital image-based dietary assessments (DIDAs). While specialized deep learning algorithms have been developed for DIDAs, the advent of multimodal large language models (MLLMs) with computer vision has shifted focus toward their potential use for automated, general-purpose food image analysis in personal and clinical contexts. Recent evaluations show mixed performance, with some individual MLLMs exhibiting systematic errors in portion size and nutrient estimation despite overall positive correlations, and occasional unsafe recommendations. Factors like fiducial markers and optimized prompting may enhance accuracy, but standardized head-to-head comparisons of leading MLLMs remain scarce. This project addresses this gap by evaluating three leading MLLMs against reference values using standardized DIDA protocols.
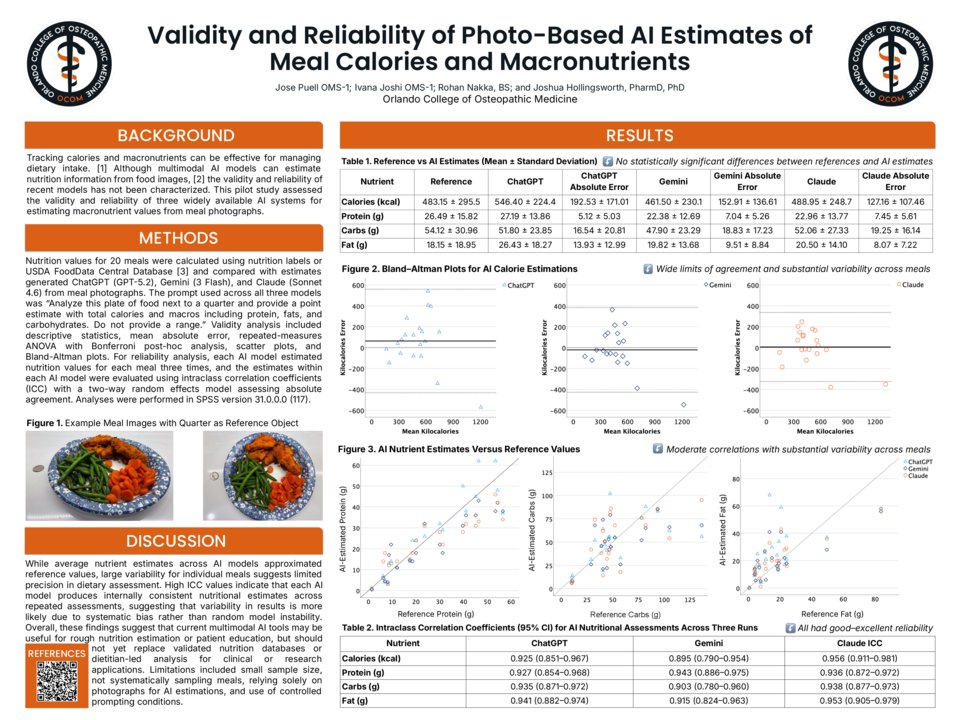
Methods: Twenty diverse meals were prepared and weighed using a validated digital kitchen scale. Reference nutrition values (kilocalories, protein, carbohydrates, fat) were calculated from USDA FoodData Central/FNDDS and nutrition labels. Each meal was photographed at 45° and 90° angles with a neutral background and a U.S. quarter as a reference object. The images were then analyzed by ChatGPT (GPT-5.2), Gemini (3 Flash), and Claude (Sonnet 4.6) using the following prompt: “Analyze this plate of food next to a quarter and provide a point estimate with total calories and macros including protein, fats, and carbohydrates. Do not provide a range.” Each meal was assessed three times per model.
Results: There were no statistically significant differences between model estimates and reference values. However, Bland-Altman plots of kilocalories indicated wide limits of agreement and substantial individual meal variability across models, as did scatter plots for protein, carbohydrates, and fat. All models exhibited excellent within-model reliability (ICCs 0.895–0.956).
Discussion: Although MLLMs yield reasonable average nutrient estimates and relatively high internal consistency, considerable meal-level errors and systematic biases restrict their precision for robust dietary tracking. These tools may aid in rough nutritional estimation or educational purposes but are not yet reliable substitutes for validated databases or professional assessment in clinical or research contexts. Limitations include small sample size and relying solely on photographs for estimations. Future studies should assess larger, more diverse samples with refined strategies, such as stating food items within the prompt and food database integration.